|
|
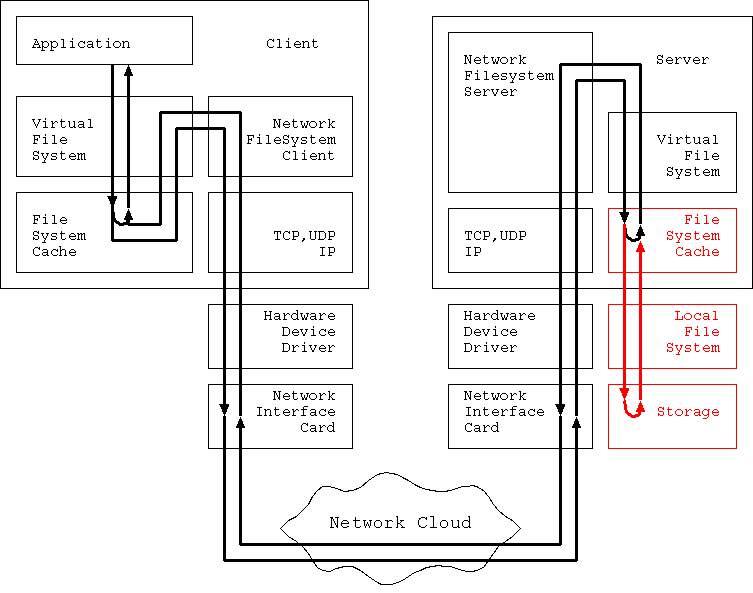
本章では図4の赤い部分、 Server File Cache から Storage までの経路に焦点を当てる。 ここは最後のパス、 Storage と IO しなくてはいけない 場合に必ず通るパスである。
図上では Server File Cache, Local File System, Storage は 3つの異なるユニットであるかのように描画しているが、 実際にはこの3ユニットの性能と特性は互いに影響しあって 全体で1つの性能を引き出す。 このため、この3つのユニットはバラバラに評価するわけには行かない。 普通に言う場合は、 この3つのユニットの性能を逢わせて Local File System の性能 と呼ぶ。
広義の nfs では、 Storage の部分は他の物にもなりうる。 例えば Network Printer にすると、 Printer Server にすることもできる。 しかし、ここではこのような場合は考慮しないことにしよう。
Local File System の性能を評価する場合、 評価軸は 3つある。 堅牢性(robustness) と IO performance、そして functionality だ。
Functionality とは、 たとえばバックアップを取る場合 Snapshot をとれる、 などの補助的な機能の事だ。 確かに補助的な機能ではあるが、 server 運営という観点から見れば重要でもある。 しかし、これの機能に関しては最後に言及する。
IO performance とは ようするに Local File System にリクエストを投げてから 結果が得られるまでの時間(Latency) とか、 1秒間にどれほどの命令数を、あるいは何バイトを読み書きできるか (Throughput) とかの事だ。
IO performance は理解しやすい概念なので、 性能表を作る場合でも top にすぐ現れる。 HDBench や iozone のように何Mbyte/sec で読めて、 何Mbyte/sec で書けるか、 という事を計測するのは良くあるベンチマークだろう。
しかし、IO performance に優先する評価軸がある。 それが robustness だ。
ファイルシステムが堅牢である という事を次のように定義しよう。
そもそも、ファイルシステムにデータを書き込もうとするのは、 そのデータを確実に保存して欲しいからだ。 もし、データを保存する必要性が全くないなら、 そもそも nfs なんていらない。 情報はファイルに保存する必要なんかない。 全て /dev/null に送り込んでやれば、 きれいさっぱり消えてくれる。 この処理方法以上に早い処理は存在しない。 IO performance は最速になるだろう。 でもこんなファイルシステムはユーザーにとって何の価値もないだろう。 だからこそ、ファイルシステムにファイルを書き込もうとするわけで、 そのニーズは Local File System に対する書き込みだろうが、 nfs に対する書き込みだろうが、変わらない。
nfs の書き込みに対する最終的な保証は、 nfs Server が nfs Server 上の Local File System に命じて、 Storage にデータを書き込む事によって実装されている。 だから、nfs Server の最終的な信頼は 結局 Local File System の実装そのものに依存している。
しかし…ディスク上にデータを書き込むと言う行為は、 当然物理的な 変化 を意味する。 そしてどんなに確率が低くても計算機も物理的な存在である以上、 変化 は 破壊 の危険性を伴う。 もし、この 変化 の最中にその変化を制御しているシステムが停止したら、 当然 破壊 は一気に高い確率で襲い掛かってくる。
実は、 破壊 が実際の形をとって現れる確率は、 変化 のさせ方に高く依存している。 Robust なファイルシステムは、 破損確率が最低になる書き込み手順を 満たすことで作る。
ファイルシステムがファイルを管理している以上、 ファイルシステムが破損したらファイルデータを参照できなくなる。 だから条件の 1 なしに条件 2 は成立しない。 しかし条件 1 が成立するだけでは、 条件 2 は成立しない。
条件 2 は軽視して良い条件ではない。 ユーザーがデータを書き込もうとする度に、 そのファイルを破損するリスクを負え、 というのはファイルシステムとして間違っている。 ファイルのデータが壊れているが ファイルシステムは無事です、などと言われて喜ぶ nfs ユーザーなどどこにいるだろう? ユーザーは nfs システムなど崩壊しても構わないから、 おれのデータを返せ と言うだろう。
このニーズは、 read only でマウントしている nfs であっても変わりはない。 read only のファイルシステムに書かれているデータを 書き込む人間(たぶん管理者)だって、 無駄なリスクを負いたくはないだろう?
条件 3 は復旧作業という観点から重要だ。 仮に復旧時にあるプログラムを実行するとファイルシステムが完璧に 回復させられる方法があっても、 ファイルシステムの復旧に 3000年かかるのでは その方式は意味がない。 実際、旧来のファイルシステムには fsck という起動時の ファイルシステムチェックプログラムがあるが、 昨今の HDD の容量の増大によって、 fsck に必要な時間の増大が徐々に非実用的なレベルにまで 増えて来つつある。 この条件は以外と重要なのだ。
厳密に言えば、条件2 を満たすのは容易ではない。
HDD の容量が 1Gbyte、Memory の容量が 4Gbyte だとしよう。 同じファイルに対して上書きをも含めて 10Gbyte 分の書き込み情報が 非同期書き込みで与えられたとしよう。 全記憶容量が 5Gbyte しか存在しない以上、 10Gbyte 分の書き込み情報は一度には HDD には反映できない。 と言うことは、 この非同期書き込みは途中で一度 HDD に反映されることになる。
しかし、その反映イメージはユーザーにとって 都合の良い単位とは限らない。 変な所で書き込みが止まった後、 システムが停止したら、 ユーザーから見たら破損したファイルになってしまうだろう。
条件2 を満たせるのは HDD に十分な空き容量があること、 Application が十分小さい、 しかもパフォーマンスに悪影響を与えない程度には十分大きい単位で Commit が発行されることが必要になる。
nfs の場合、 nfs request が小さい単位で行われるので、 大抵の場合問題は生じない。
このRobust なファイルシステムの実装には3つの前提がある。
1つには Robust なファイルシステムの定義にもある通り、 Storage の物理的破損はファイルシステムのような論理構造では 回避・復旧は不可能なのでそれらに対する責任は負わないことだ。
2つ目は、 Storage はある単位での write リクエストに対して、 完全実行か無実行になることだ。 もっと分かりやすく言えば、SCSI IO request の単位でもいいし、 IDE のコマンドの単位でもいいし、 sector 単位の書き込みでもいいから、 とにかく「この命令を実行し始めたら、これだけは最後までやり遂げる」 という基本単位を保証してもらわなくてはいけない、と言うことだ。 一般には、これは Sector 単位で保証されていて、 ある Sector を上書きし始めたら、その Sector の書き込みに関しては HDD 側が保証するのが一般的だ。 でも、ものによってはもっと大きな単位での保証をする Storage もある。 この保証が無くなった場合も Storage が破損した、と呼ぶ。
3つ目は、 Storage に対する書き込み命令は与えた順序通りに実行保証が なされること、だ。 A,B,C という命令がこの順序で発行された場合、 AとCは実行されるが B は実行されない、 という状態はあってはいけない。 さらに、A,B,C が同じ部位に対する影響を与える場合、 ちゃんとこの順序で書こうとした場合と同じ結果が残らなくてはいけない。 現実の書き込み順序はともかくとして、 結果は A, B, C の順序で実行しようとした結果と同じでなくてはいけない、 と言うことだ。 しかも、AとB は実行できたが C は完達できなかった、 という場合も保証されなくてはいけない。
実はこれらの前提が成立する場合の Robust File System の実装方法は、 広く知られている方法だけで3種類ある。 Softupdate , Log Structured File System , そして Journalized File System だ。
そもそもファイルシステムやファイルのデータは、 どのようなタイミングで壊れるのだろう? 少なくとも OS を終了するときに umount する際には 全てのファイル情報でまだ未記録なものを書き込むことになっている。 こうすると ファイルシステムもファイルのデータも壊れないことになっている のだから、 書き込みを全て完了した後に破損していることはあり得ない…。
実は、この書き込み手順と破損のポイントを丁寧に追い回した結果、 ファイルの破損は書き込み手順の最中で発生すること、 書き込み手順によってはファイルのデータが壊れない (当然ファイルシステムも壊れない) 事が判っている。 壊れない書き込み手順に従った書き込みしか行わない技術が Softupdate である。
|
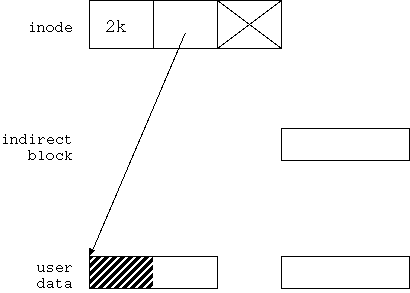
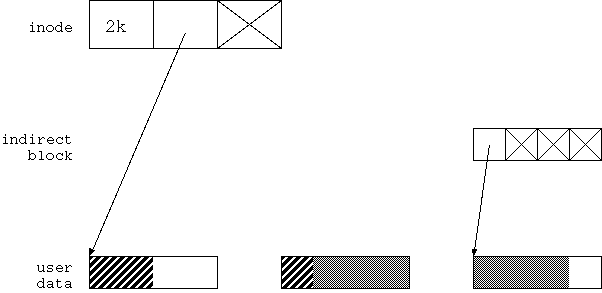
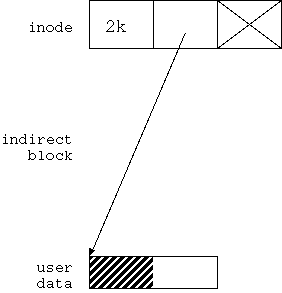
Softupdate 技術を理解するには、 ファイルシステムを破損させる書き込み順序を理解するのが一番だ。 そこで、仮想的なファイルシステムを考えてみよう。 簡単な例として図 4.1 のような例を考えよう。
図4.1 は 2kbyte のデータを持った通常ファイルと その管理構造の例を示している。
まず上段には、inode が1つある。 inode は、file size、 user data block を直接指し示すポインターが一つ、 1次間接ブロック経由で user data block を指し示すポインターが 一つ、存在する。 ただし、間接ブロックポインターは現在使われていない。
中段には間接ブロックを表示するが、 間接ブロックポインターが現在使われていないので ここは今、空欄になっている。
下段には user data block が存在する。
1block は 4kbyteとする。
ユーザーデータは現在 2kbyte しかないので、
このうちの半分(斜線で示した分)が
ユーザーデータで埋まっている。
残り半分はゴミだ。
|
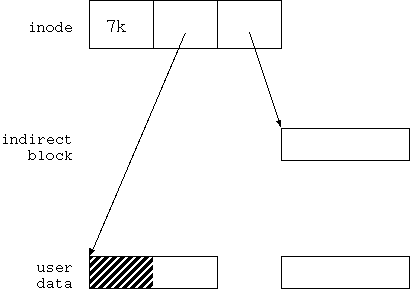
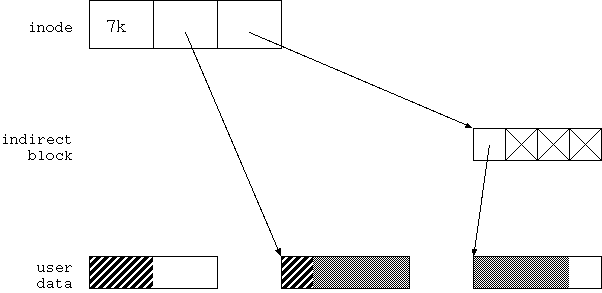
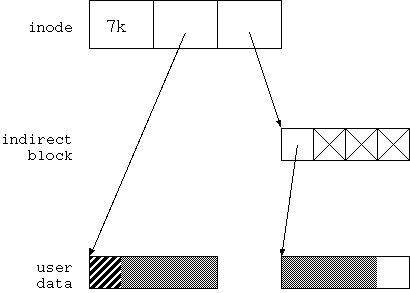
図4.1 の状態にあるファイルに offset=1kbyte、length=6kbyte でデータを書き込むことを考えよう。 結果は図 4.2 のようになるはずだ。
図4.2 では、 まず inode の間接ポインターが有効になっていて indirect block を指している。 indirect block の最初のエントリーが有効に、 それ以外は無効になっている。 indirect block の最初のエントリーは user data block を指している。
user data block は2つ存在する。 最初の block の 先頭 1kbyte は図4.1 と同じデータになっている。 残り3kbyte と、2番目の user data block の先頭3kbyte は 新しく書き込んだデータになっている。 2番目の user data block の最後の 1kbyte はゴミだ。
さて、問題は、図4.1 から図4.2 へどのように遷移するか、だ。
|
|
|
|
|
|
|
|
|
|
|
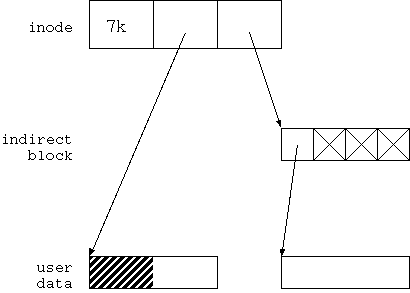
まず、最初に「悪い」例を示そう。 図4.3 に示すのは ext2 などが実際に行う書き込み順序を モデル化したものだ。
図4.3 (b) に示すように、 まず、最初に行うのは user data block 並びに indirect block 領域の確保だ。 ここでは、indirect block 1つ、user data block 1つが 確保されている。
この段階ではファイルシステムは「破綻」はしていない。 確かに余分なブロックが確保されているので、 これを解消しないとファイルシステムとして使える block 数が減ってしまうが、 別の言い方をすればそれ以上の被害はない。 従って、この状態を放置しても大きな問題は生じない。 もちろん、解消することも可能だし、 fsck でこの問題を解決するのに必要な時間もあまり多くない。 さらに言えば、この問題を解決方法は一意に定まり、 その修正で破損するものは何もない。 従って、この段階ではファイルシステムも、ファイルも破綻していないのだ。
図4.3 (c) に示すように、 2ステップ目の作業は inode の更新だ。 inode は最終段階と同じ状態に更新される。
この段階で最初の破綻が生じる。 何が起こったのか理解するために、 この段階でシステムが停止した場合を考えてみよう。
まず、inode に登録されているファイルサイズが 7kbyte になっている。 ということは user data block の最初のブロックの後半 2kbyte 分が このファイルのデータとして有効になっている。 前に言った通り、ここにあるデータはゴミなので、 この段階でファイルは無効なデータと有効なデータの切り分けが できない状態に陥っている。
さらにまずいことに、 inode は indirect block を指し示している。 が、この indirect block は全く初期化されていない。 従って、この indirect block の最初のポインターが どの block を指し示しているのか、不定である。
このポインターが存在しない block を指し示していた場合は 最良の ケースだ。 問題はすぐ検出することができるし、 結果として inode のサイズは少なくとも 4kbyte に切り詰めれば良いことが判る。 indirect block は解放すれば良い。
もしこのポインターが、すでに存在している 他のファイルのブロックを指し示していた場合はどうだろう? まず、最初に問題になるのはセキュリティだ。 本来アクセスできてはいけないファイル、 例えば /etc/shadow などのセキュリティ上のキーファイルが使っている block を指し示していたら、 これは Security Violation になる。
この状態を回復させるために、 各ファイルが指し示している user block を全て相互照らし合わせて重複を発見できたとしても じゃぁ、本来はどちらの持ち物だったのか、 確定することはできない。 ファイルシステムはファイルの中身を調べて判断する能力は 持ち合わせていないからだ。 もし、間違った側のファイルから block を引き剥がしたら、 そのファイルは破損するだろう。 /etc/shadow の最初の block だったら… たぶん、二度と root で login できないシステムになってしまう。 つまり、もう一意回復はできないことになる。
このポインターが偶然にも「これから本当にポイントして欲しいブロック」 を指していたらどうだろう? この場合、ファイルシステムとしては矛盾は生じない。 でも、それは偶然 図4.3(d) の状態になっていた、と言っているだけだ。 図 4.3(d) に存在する問題をまだ解決できていない。
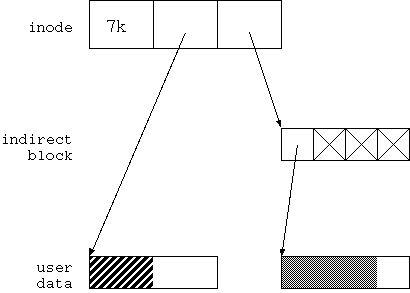
図 4.3(d) に示す通り、第3ステップは indirect block への書き込みだ。 これが無事に終了した場合、 ファイルシステムとしての矛盾はなくなる。 つまり、fsck を行った場合 ファイルシステムには異常がなかったとされる。
しかし、この場合、ファイルが破損した状態のままだ。 7kbyte のファイルは 2kbyte の旧来状態のファイルデータと、 5kbyte のゴミデータから成り立っている。 ユーザーから見ればファイルは壊れたままだ。 ゴミデータの中には都合の悪いものも含まれているかも知れない。 /etc/shadow の古いページが残っていたら? それも Wnn 君のパスワードを変えただけで root 君のパスワードは 変更していない頃の block が再利用されていたら? 想像するだけでも楽しい Security Violation の山が発生する。
図4.3(e) になってもこの状態は続く。 2番目の user block の上書きが終了しても、 1番目の user block はまだおかしいままで、 ファイルは破損している。
図4.3(f) になってようやく、 ファイルは破損から回復する。
結局ファイルシステムとしては 図4.3(b) の直後から 図 4.3(d) の直前までの間、破損している。 ファイルとしては 図 4.3(b) の直後から 図 4.3(f) の直前までの間、破損している。 この間にシステムダウンを起こせば、 ファイルは、あるいはファイルシステムは破損してしまうのだ。
どちらの破損も、 修復可能なものも、修復不能なものもありえるが、 最悪なのは、どちらの状態になるのか判らない、と言うことだ。 このため、 正常な状態であると自信を持って言える 状態には絶対にならない。 fsck を実行して ファイルシステムが矛盾していない とは言えても、それが正しい状態だという保証はない。
ファイルシステムを sync mount にすれば壊れない
と信じている人もいるみたいだが、
この更新手順に従うシステムでは、
sync mount でも壊れるファイルシステムは、やはり壊れる。
sync mount はあくまでも
書き込みシステムコールから戻ってきた場合に
正常に書き込めていることを保証するものだ。
書き込み手順を変更するわけではないので、
ここで書かれた書き込み手順で書き込んだら、
相変わらずファイルシステムは破綻する危険性を負う。
sync mount と async mount の違いは、
自分が明示的に行ったある書き込みに関して、
やった当人が明確に「不幸に陥ったことを自覚できる」かどうか、
程度の違いしかない。
|
|
|
|
|
|
|
|
|
では、今度は Softupdate の書き込み方を見てみよう。
図4.4(a) は当然いままでと同じだ。
図4.4(b) に示す通り、悪い例と同様、 Softupdate の場合もまずは data block の確保から始まる。 ただし、悪い例の場合は user data block が 1 個だったのに対して、 こちらは user data block を 2個確保している。
図 4.4(c) が悪い例と最も異なる点だ。 Softupdate では、user data block 並びに indirect block など 新たに確保した block のイメージを先に更新する。
ここで user data block が 2 個である理由が判る。 Softupdate は必ず Copy on Modify 戦略に従う。つまり 上書きは絶対にしない のだ。 上書きをして古いデータを書き換えてしまった直後にシステムがダウンしたら、 上書き部分の変更は反映されているのに、 他の部分は古いまま、という中途半端な破損状態に陥るのを防ぐためだ。
さらに、user data block と indirect block は、 どれをどの順序で変更しても構わない。 ファイルシステム的には これら 3 つの block は相変わらず、 どの inode からも参照されていない、 over allocated な存在でしかない。 ファイルシステムからすれば ゴミイメージ が別のゴミイメージに書き換えられただけなのだ。 従って、これらをどの順序で書き換えても構わない。 ただし、必ず全て書き換えてからでないと次のステップへ移動してはいけない。
図 4.4(d) ではじめて inode が更新される。 inode は一般に HDD の sector サイズよりも小さいので、 この更新は all or nothing で実行される。 従って、inode が「破損」する可能性は考えなくて良い。
inode が更新されると、 今まで over allocated だった block が全て有効になる。 これに伴って、ファイルへの変更が一気に有効になる。 逆に今まで参照されていた block が over allocated な存在になる。
図 4.4(e) が最終状態である。
ここへ遷移するために、
(d) の段階で over allocated になった古い block を全て解放する。
以上見ての通り、 Softupdate の手法ではファイルも、ファイルシステムも、 破損する瞬間というものは発生しない。
Softupdate は FreeBSD , OpenBSD , NetBSD などの *BSD 系列では、 もう標準的に実装されている。 NetBSD では softdep と呼ばれている、など若干名称は異なるようだ。
また、 耐故障 Linux のページ のように Linux でも似たようなものが存在する。 ただし、 このページ、Linux kernel 2.2.15 用のパッチを最後に、 更新されていないように見える(2001年12月16日現在)。
この方式の最大のメリットは、 ファイルシステムの物理フォーマットを何ら変更することなく 堅牢性が確保できる、という点だ。 過去との互換性を保持しつつ robustness を確保したい場合、 強い武器になる。
この方式の最大の弱点は、 自分が使っているシステムが Softupdate を採用していない場合、 そのシステムに Softupdate 機能を追加するのは すさまじく辛い という点だ。
いい加減にコードを組んでも、 運が悪ければ(いや、運が良いのか?)ファイルシステムは破綻しない。 Softupdate のデバッグは とりあえず動く 系のコードの中から、 正しく動く ものをえり分ける作業になるので、 明確な問題点を判別する道具立てが揃っていないのだ。 ひたすらコードが正しいかどうか確認し続けるのは苦痛に満ちた作業であり、 しかもそれをぐちゃぐちゃと変化し続けるコードに対して行うのは 地獄でしかない。 耐故障 Linux のページ が更新を停止しているのは、 Linux Kernel の 2.3.0→2.4.16に至る膨大な変更の山の前に、 一時的に更新を諦めているのではないだろうか。
Log Structured File System(以下 lfs)は、 同じ問題に Softupdate とは異なる戦略で対処している。
Softupdate の書き換えパターン、特に悪い例を見ると判るが、 ファイルシステムが破綻するのは overwrite や削除の時だ。 もちろん、全ての overwrite が悪いわけではないのは、 Softupdate が示す通りだが、そもそも overwrite が存在しなければ ファイルシステムは破綻しない。
lfs は、全てのファイルシステム書き込みを Append で行ってしまおう、 という戦略だ。 そのためならばファイルフォーマットが過去と全く互換性がなくなろうが、 何をしようが構わない。
HDD を仮想的な巨大な1本の磁気テープである、と見なしてみよう。 ここに、図4.1 と同じ構造のファイルが存在する場合、 図 4.5 のようになる。
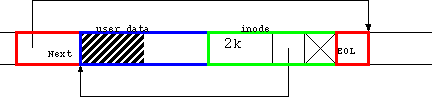
|
とりあえず、識別しやすいように色を付けてみた。 左から順に見ていくと、 まず、赤で囲まれた、この Log の終りを指し示す Next フィールドがある。
次に、青で囲まれた、user data block の 1 つめが存在する。
次に、緑で囲まれた、inode が存在する。 inode にはファイルが 2kbyte であること、 最初の block への direct pointer が青の先頭を指し示していること、 indirect pointer は nil になっている事が、記されている。
最後に、赤で囲まれた、End Of Log(EOL)マーカーが存在する。 これは Next フィールドから EOL マーカーまでが、 1セットの Log であることを示しているだけで、 この後ろに Log があるかどうか、は後ろを探ってみないと判らない。
見ての通り、一続きの領域に記録されていることを除けば、 論理構造は Softupdate の図4.1 と何ら変わらない。
ここに、offset 1kbyte から 6kbyte のデータを書き込む、 と言う処理を施した場合、図 4.6 のようになる。

|
まず特徴的なのは、 必要な変更情報が全て先の情報のうしろに Append の形で記録されている点だ。 このため、仮にこの更新領域全体を完全に更新できていない場合、 この部分は丸ごと無効になる。 直前の領域までが有効な情報になるので、 変更はなかったことにできる。
右側から順に inode, indirect block, user data になっている。 もし、user data の中に変更のない block があったならば、 その部分は前の block がそのまま利用される。
このように変更分を「追記」で保存し続けるので、 Log Structured File System と言うわけだ。
見ての通り、inode もどんどん追記していく、 と言うことは有効な inode の位置が移動し続けると言うことになる。 となると、ある inode 番号を持った inode がどこにあるのか、 どうやって判るのだろう?
実は、i-node の i は index の略である。 このことから判るように、 本来(というよりも、もはや 古来 と言った方が良い気もするが) unix の最も初期の File System である File System(FS) では、 あるファイルの inode 番号はそのまま、 inode 配列の先頭から見て何番目に目的の inode 構造体が存在するのかを 示していた。 これを可能にするために、 Storage をフォーマットした段階で、HDD の先頭領域に inode 領域というものが確保されていた。 この領域の大きさがそのまま inode の個数を規定し、 それがそのまま FS 上に確保できる directory 並びに file の 個数を決定した。
Fast File System(FFS) になって、 ディスク上の inode の存在する位置は変化し、 inode の利用割り当てアルゴリズムも変化したが、 inode 番号と inode 構造体の関係は全く変わっていない。
この inode 専用領域の確保と inode 番号と inode 構造体の存在位置の 直接的な対応関係は、 システムを単純にする代わりに数多くの犠牲を、利用者に強いて来た。 最大の問題点は inode の過不足に対処できない という点だ。
inode は Storage をフォーマットする際に領域のサイズが決定される。 と言うことは、 フォーマット時に inode の個数が決まってしまうと言うことになる。 inode が多すぎればディスクスペースを浪費することになる。 inode が少なすぎればディスクスペースがまだ余っているのに ファイルを作成できなくなる。 しかし、Storage をフォーマットする段階で、 利用者のファイルの平均サイズを決定することなど出来はしない。 しかも、この平均サイズは時と共に変化するだろう。 ある瞬間に最適だった inode 個数がいつまでも最適であり続けるという 保証もない。
この問題を解決するために、 最近のファイルシステムは 可変長の inode 領域をサポートするようになってきている。
可変長の inode 領域を実装するには、 場合に応じて inode 領域が増減できなくてはいけない。 その一方で inode 領域全体が inode の配列 としての見方を変更するのは得策ではない。 こう考えると、 inode 領域はそれ自体が一種のファイルの形を取るのが得策である。
実は同じ事が Allocation bitmap についても言える。 HDD を 計算機がまだ動いている最中に追加したり外したりできるようになり、 さらに Logical Volume Manager という層が、 複数の HDD を論理的に1つの storage に見せることができるようになった結果、 Storage のサイズが File System が動作している最中に 動的に変化するようになった。 結果として、disk 上の block の利用状況を表現している allocation bitmap のサイズも動的に変化する必要が出てきた。
このように、従来固定サイズだった ファイルシステムを管理するために必要な Metadata の尽くが 可変長サイズになる必要が出てきた。
このような 可変長 Metadata を実装するために、 最近デザインされたファイルシステムは皆、 root inode という方式を使っている。 root inode 方式にはいくつかの実装形式があるが、 その一つを 図4.7 に示す。
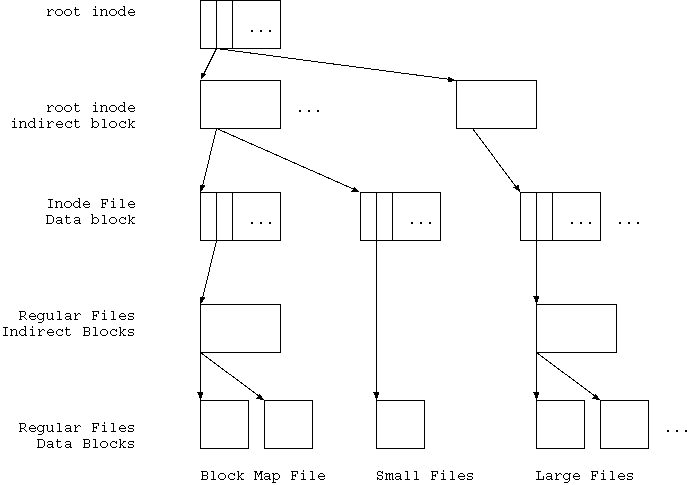
|
見ての通り、root inode 方式の場合、 ファイルシステムリソースは、 root inode と言われるたった一つの inode がまず存在する。 root inode だけは固定の位置に存在し移動しない。
root inode が indirect block を指し、 indirect block が inode file data という inode 配列 を表している ファイルを形作る。
inode file data で表現される inode の最初のいくつかは、 利用目的が決まっている。 Block Allocation Map File はその中でも必須のものの一つだ。 他に Access Control List(ACL) なども必要になる。
LFS も copy on modify 方式なので、 論理構造上は Softupdate と同じ変更順序を守れば、破綻を起こすことはない。 つまり root inode 以外のデータは全て、 copy on modify で変更する。 Log として append するのだから当然だが。 最後に root inode を変更すると、 古い tree から新しい tree に切り替わるわけだ。
無限のディスクスペースがあれば、 これで全て終わるのだが残念ながら Storage はすべからく 有限の容量しかない。 と言うことはどうにかして使っていない領域を回収しなくてはいけないわけだ。
まず、図4.8 のように HDD を Segment という一定サイズの領域に分割し、 Segment をリンクリストで接続して仮想的な磁気テープを構築する。 これを Segment chain と言う。
Segment chain は同一の HDD 上に存在する Segment だけから 成り立つ必要はない。 複数の HDD からの Segment を chain しても構わない。

|
Segment chain の先頭の方から利用していくと、 徐々に残っている Segment の数が少なくなっていく。 残りが少なくなったら、図4.9 のような Compaction を行う daemon が自動的に空き領域を回収することになる。
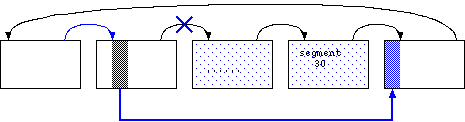
|
まず、Segment Chain の既に利用した領域に、 有効な block が全く残っていない Segment があった場合、 その Segment は Chain から一旦外して Segment Chain の末尾に 繋ぎ直す。
空っぽの Segment が存在しなかった場合は、 比較的空き領域の多い Segment を選んで、 そこにあった data block 内容をLog の末尾にコピーし直す。 こうするとその Segment は完全に空になる。 このように data block を詰め直す作業を Compaction と言う。
Compaction 作業時には、 不連続になってしまった data block を連続に直すという事も行われるのが 一般的だ。 LFS では小さな write が頻発すると、 data block 同士の間に利用されなくなった inode block が 挟み込まれる事になる。 data block が不連続になると read 性能に悪影響が出るので、 この問題も一緒に解決するのだ。
LFS 実装で直面する困難には、もうひとつある。
旧来のファイルシステムでは Directory は Long File Name 対応のために、 ファイル名フィールドは可変長になっている。 このため、ファイル名フィールドは Link list で接続されている。 結果、ファイルの create/open/remove などで directory entry を検索する必要がでると、 リンクリストを手繰り続ける以外方法がない。
これは、directory entry 数に比例して create/open/remove 処理は 時間がかかる、という事を意味する。 Storage スペースが大きくなり何十万個というファイルが 1つの directory 下に置けるようになってくると、 これはパフォーマンスに大きな悪影響を与えるようになる。
この問題を解決するには、 directory entry を平衡木で管理すれば良い。 平衡木を用いれば directory entry 数 n に対して、 検索が O( log n ) で済むので entry 数の増加にも、 遥かに柔軟に対応できる。
しかし、この「平衡木」という所に大問題がある。 平衡木、特に B-Tree やその変種である B+-Tree, B*-Tree は、 恐ろしく実装が困難なのだ。 基本原理は簡単なのでプログラミング演習でよくテーマに用いられるのだが、 まともに実装できる生徒などほとんどいない。 それは別に生徒の質の問題ではない事は、 世のアルゴリズム辞典の B-Tree の実装例の大半に微細な、 しかし十分致命的な、 バグがあることからも判る。
この点に関しては特に解決策は存在しない。
説明が長くなったが、 LFS は実際に実装するのは極めて難しい。 Softupdate はデバッグが困難なだけだったが、 LFS は Compaction、root inode、B-Tree という3つの アルゴリズムが複雑で、実装が困難なのだ。 さらにこれらが高速に動作するように実装するとなると 悪夢にも等しい。
このため、LFS の実装プロジェクトで 2002年1月末日の段階で 凍結状態に陥っていないのは、 唯一 NetBSD だけだ。 しかも NetBSD の実装はまだパフォーマンスチューニングのレベルまで 到達していない。
Journalized File System(jfs) はこれまでのべてきた2つの方式、 Softupdate LFS とは大きく異なる戦略を取っている。
Storage への変更を行っている最中に電源断などが生じた場合、
その瞬間、Storage は中途半端な変更の状態に陥るのは当然だが、
では、再起動後続きができないのはどういう理由によるのだろう?
答は当然、
「何をするつもりだったのか完全に忘れているから」
ということは、まずこれから何をするのかを先に記録し、 それから実行すればこの「忘却」問題は解決する。 このような方式を Journaling と呼び、 このような戦略を取る file system の事を jfs と呼ぶ。
厳密には、上記の定義は「広義の」という言葉が必要になる。 「何をこれからやろうとするのか」を記録する方式は そもそも database の世界で transaction 、 つまり ある一セットの命令を完全に終了させるか、 あるいは全くなかったことにするか、 どちらかにできる 状態を実装する方法の1つとして提案された、 transaction log 方式とか、 intent logging 方式とか言われるものと、 一部やっていることが同じなので、 名前が衝突するのだ。 Journal をどこで、どのように取るのかによっては、 「狭義の」Journaling というものが存在してしまう。 それも「流派」によって似たようなものの呼び名が変わるのだ。
そこで、以下の説明では、完全に私独自の名前を割り振ることにする。 以下の名前が一般的に周知のものであるとは思わないで欲しい。 なるべく同じ、あるいは似た、名前をつけようと努力はするが、 自分が実際に jfs を目にする際は、 どういうやり方のことを何と呼んでいるのか、 自分で調べ直すことをお勧めする。
jfs にはいくつかの種類がある。 それはおおざっぱに言って以下のように分類できる。
それぞれ得手不得手のジャンルがあり、 またどのようなハードウェアサポートがあるのかによって 優劣が変化するので一概にこれがよい、 などの評価は難しい。
また、この分類方法だと「両方」という file system も存在する。 たとえば tranzaction logging と Storage IO logging の両方を取り、 evaluation 順序も状況に応じて in order only だったり out of order に変わったりする、 などというものも作り得るし、 ハードウェアの補助があればこれらは実行時のオーバーヘッドなしで 実装が可能だ。
ただし、これらのハードウェアの補助がない場合の評価は難しい。 jfs は基本的に log を書いて から ほんちゃんを書く 、さらに log に書き終わったことを記録する という処理手順を踏む。 このため、単一の Storage に両方を記録する場合は、 Softupdate LFS と比較して、Storage に対する書き込み量が最も多くなる。 このため、 十分にランダムな書き込みに対する throughput 計測を行った場合、 メディアが純粋に書き込み量に比例して書き込み時間がかかるならば、 jfs は最も成績が悪くなることは既知である。 別の言い方をするならば、file system に対する負荷は 「十分にランダム」ではないし、 Storage も書き込み量に比例した書き込み時間になるわけではない、 という事が知られており、 そこに jfs の 勝ち目 も存在するわけだ。
旧来の FFS 互換の、あるいは FFS をベースにしたファイルシステムには 32bit で管理されていることから来る容量の上限や、 directory element に対する線形性など、 問題が多いことは LFS の所ですでに述べた。 jfs は一般に新規に作られることが多いので、 これらの問題に対処するためにも物理フォーマットは全く新規に デザインされることが多い。 必然的に旧来のファイルシステムとの互換性はなくなる。
しかし、これは jfs が旧来のファイルシステムとの互換性を持たせられない、 という意味ではない。 Journal を記録する領域さえ用意できれば jfs は作れるのだから。 その最も典型的な例が Linux の ext3 だ。
ext3 は ext2 と物理フォーマットは全く変わらない。 実際、ext3 は実際の disk IO をすべて ext2 のルーチンに依存している。 ext3 は ext2 にファイルを1つデフォルトで確保する。 このファイルはユーザーからは見ることはできないし、IO もできない。 このファイルは Journal を保存するために使われる。 それ以外の構造は ext3 と ext2 に違いはない。 実際、ext3 として使われていたファイルシステムを unmount し、 ext2 として mount し直すこともできる。
ext3 に対する IO リクエストが発生すると、 ext3 は実際に変更を disk に反映させる前に、 Journal ファイルにその変更を記録する。 Journal ファイルに記録された変更は、 その後 asyncronous に ext2 ファイルシステムに対して反映される。 理論的には Journal ファイルには dirty page に関する情報がそろっているので、 これで問題はない。
旧来のファイルシステムとの互換性をもった、 あるいは旧来のファイルシステムを一部変更して作られる jfs は、 一見優れているように見えるが、 実はとても重要な requirement が旧来のファイルシステムに求められる。 旧来のファイルシステムは 同期書き込みを必ず、バグなく、サポートしなくてはいけない のだ。 そして、この条件を満たしていない好例が ext3 である。
ext2 は複数のバグが絡み合って、 結果として同期的書き込みが全く保証されない。 user data の disk への書き込みは、 write システムコールに対する O_SYNC フラグを付与しても、 fsync システムコールを呼び出しても、 sync システムコールを呼び出しても、 保証されない。 umount によってのみ、dirty page は 100% 反映される。
と言うことは、 ext3 層が ext2 に Journal を書いてくれと頼んでも、 Journal 記録が disk に書き込まれる保証はない という事を意味する。 さらには、ext2 は書き込み順序にエレベーターシークアルゴリズム などを用いるので、 Journal ファイルへの Journal 記録の反映順序保証さえない事になる。
つまり、Journal ファイル上の記録は破損しており、 Journal を反映させるとファイルシステムを破損させる危険性があるのだ。 というか、実際、不意の電源断の後、 ext2 として正常だったファイルシステム を ext3 として mount したら、 破損した Journal にぶち壊された経験がある。
ext3 を利用する場合は、 Journal を ext2 領域外に確保することが肝要である。
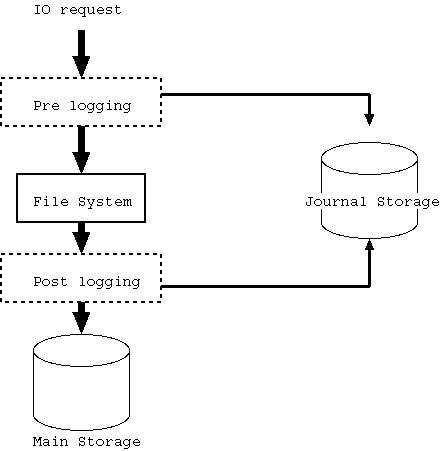
|
jfs において「Journal を取るポイント」というのはいくつかあり得る。 ただし、本質的には図4.10 にあるように Pre logging 型 と Post logging 型 の2つに落ち着く。
図4.10 を理解するために、まず Pre logging 並びに Post logging の 無い場合について説明しよう。 Application 等から IO request が File System に到達すると、 File System はそれを解釈し、 Main Storage への request に変換して発行する。
Pre logging 型というのは、 File System への IO request をほぼそのままの形で Journal に保存する 方式のことを言う。 一方で、Post logging 型というのは、 File System が Main Storage に対して発行した、 あるいは発行する予定の、 Storage request を Journal に保存する。 どちらにも一長一短があって、 一概にどちらが良いとはきめられない。
話の早い Post logging 型から話を始めよう。
Post logging 型の特徴は Storage request、 実質的に Sector に対する 書き込み request を Journaling している点にある。
同じデータを同一の Sector に対して上書きしても ファイルシステムとしては何も破損しないので、 Journal の Main Storage への適用は何度でも行える。
また、同一 Sector への書き込みは最後の1回だけが実行されれば良く、 Main Storage への書き込み順序は(Journal として矛盾しなければ) どの順序で行っても良いので、 Journal Storage へ記録された後は、 実質的に書き込み処理は asyncronous に、 かつ elevetor seek などの最適化を徹底して用いることができる。
ただし、基本的に File System への 1つの IO request は、 複数の Storage request に分割される。 もし、ある IO request を実行するために必要な Storage request の 一部しか Journal Storage に残っていないと、 逆にファイルシステムを破壊することになってしまう。 そのため Journal のフォーマットに Storage request set を記述する 能力が必要になる。
Main Storage への書き込み request を Journal に書き込むと言うことは、 Main Storage への本当の書き込み data 量 + 管理構造用 data を Journal Storage へ書き込む必要がある、という事だ。 Journal Storage への書き込み速度が全体の速度を律束しやすいので、 Journal Storage 自身の性能が高くなくてはいけない。 可能ならば NVRAM などを利用できるとよいが、 それはそのまま「ハードウェアコストがかかる」事を意味する。
さらに、 Journal を保存したらあとは Main Storage へはいつ書き込んでも良い、 とは言え、 Journal に記録する際にはどこに何を書き込むのかの 決定が済んでいる必要がある。 Journal にさえ記録すれば syncronous write IO request でさえ 「非同期書込みしても大丈夫」なのに、 非同期書込みをする最大のメリット、 Storage 上のレイアウトを、 近視眼的な束縛を受けることなく、 最適に配置することができる という点を放棄しなくてはいけない事になる。
Post logging 型は相対的に実装がしやすいものの、 Journal Storage の HW resource のコストが高くなることと、 パフォーマンス的にはあまり高性能を出せない、 という大問題を抱えている。 しかし、逆に言えばパフォーマンスさえ求めなければ、 Journal Storage に対する要求も低くて済むので、 廉価なシステム、ext3 や ReiserFS などではこの方式が採用されている。
Pre logging 型は IO request をほぼそのまま Journal に保存している。
基本的に Storage request よりも IO request の方がサイズが小さいと 相場が決まっているので、 同じ Journal Storage サイズならば、 Post logging 型より多くの IO request を Journal Storage に格納できる。 つまり、journal を保存してから実行を余儀なくされるまでの、 時間的余裕が大きい。 これはより最適な disk layout を決定する時間が多く与えられている という事で、パフォーマンスの点からは重要だ。
IO request が journal に保存された、と言うことは、 結果が推測できる場合、journal に保存しただけで結果が返せる、 という事を意味する。 例えば Storage への data の追加書き込み要求が来たとしよう。 Storage に空き容量が十分あり、書き込み許可があることを確認すれば、 この段階で書き込み成功を返してしまって構わない。 従来のファイルシステムや Post logging 型だと、 file system 側に dirty block allocation 等の作業を行ってからでないと reply を返せなかったのだが、 それらの処理は全て reply を返した後に行うのでも間に合う。
これは NFSv2 で特に酷く発生するが、 小さな commit write が頻発することがある。 Pre logging の場合、Journal Storage に記録を残せば、 いつでも再実行可能になるので、 commit write という性質を消してしまうことができる。 File System から見た場合、commit write は全く来ない、 という状態を作れるわけだ。 commit write のように『即時書き込み』を要求されると、 File System はそれまでの書き込みスケジュールを破棄して、 commit write を優先する必要が出てしまう。 head seek scheduling などの観点から見てこれは好ましくない状態なので、 この状態を回避できる、と言うことはパフォーマンスの観点から見て大きい。
ここまでが Pre logging 型の主なメリットだ。 見ての通り、Pre logging 型は Post logging 型に比べて パフォーマンス面でメリットが多い。
一方で、Pre logging 型にはいくつかの致命的な性質がある。
Pre logging 方式は IO request をほぼそのまま保存している。 ということは、その変更が Storage image をどのように変更するのか journal を見ただけでは全く判らないという事になる。 変更は File System の状態とセットでないと決定できない。
しかし、journal に書かれた、ある変更を storage に apply している 最中に電源断が発生したとしよう。 一般にこの場合、Storage の data image は file system としては 壊れている。 この状態では IO request を apply しようとしても、 さらに storage image を破損することにしかならないだろう。
例えば、'A' というファイルに 30 byte のデータを append しろ、 という命令が来た場合に、30byte のデータを append した直後、 Journal Storage へ「変更が apply された」事を記録する直前に 電源断が発生した場合、 Journal を再実行すると、この命令は結果として「60byte のデータ」 を append する事になってしまう。 これでは適切な journal recovery とは言えない。
さらに一般的には、 jfs の場合、File System への書き込みの最中に電源断が発生すると、 Softupdate の所で説明したような破損が発生している可能性がある。 これを発生させないように Softupdate 機能をつけてしまったら、 jounal の必然性がなくなってしまうので、 これはある意味当然なのだが、 壊れたファイルシステムに通常通りに IO request を投げて、 ファイルシステムとして矛盾が発生しない ぐらいなら、 それはそもそもファイルシステムが破損しない事を保証していることになる。 これは無理というものだ。 ので、電源断が発生してしまうと、IO request を apply できなくなる 可能性が生じてしまう。 これでは Pre logging 型は役に立たない。
Pre logging 型が使えるためには、 File System 側に Storage Snap Shot という機能が必要になる。 詳細は後述するが、 SnapShot 要求というのを File System に対して行うと、 その瞬間の Storage Image を壊さないように、 それ以降の Storage への変更を行う機能が File System に存在し、 将来、「過去のいついつに戻りたい」と言ったときに その時点の Storage Image に復帰できる、という機構だ。 Pre logging 型では、 この Storage Snap Shot を複数(2つ以上)確保できる機能が必要になる。
ある瞬間に Journal を何らかの理由であるポイントまで File System に 反映しなくてはいけなくなったとしよう。 とりあえず、今の File System のイメージは Snap Shot が取られているとする。 これを Snap Shot 'A' としよう。 この場合に、Journal の apply と Snap Shot は、次の手順で同期を取る。
上記の三ステップを全て終了する前に system down を起こした場合、 再起動後、Snap Shot 'A' に対して再度 Journal Storage の中身を反映する。
Step 3 が終了した後は、Snap Shot 'B' をベースに、 残りの Journal を apply する事になる。 こうなったら Snap Shot 'A' は(Journaling という観点から見れば) もはや必要ないので、再利用可能になる。
こうすれば、Pre logging で確保された journal を反映することができる。
Pre logging 型の journal を使う場合、 File System は、同じ条件から journal に保存した通りの順序で IO request を発行したら、 必ず同じ結果 にならなくてはいけない。
File System は、実は、順序による結果の一意決定性の保証をしなくても File System として動作するものを作ることができる。 たとえば、2つの process がほぼ同時に write() と chmod() を リクエストしてきたとしよう。 一応、順序的には『write→chmod』だとする。
この場合、File System は、
「んー。なんかこの write、時間がかかりそうだな。
先に chmod やるか」
と言って、内部で順序を入れ替えてしまっても、
実は
バレナイ
。
ばれないということは(公平性には欠けるかも知れないが)、
File System の実装としては「あり」だと言うことになる。
しかし、write() と chmod() の間の時間が十分に離れていれば、 そしてこの間にこれ以外のリクエストがいっさい来なければ、 write() と chmod() はこの順序通りに実行される。
仮に、同一のファイルに対する write() 並びに chmod() で、 しかも chmod() されると write() が実行できなくなるような場合、 外部から観察した場合のリクエスト順序 と 内部でのリクエスト順序 が一致しなくなる。 しかも、常に一定の結果になれば良いのだが、 その保証が無い場合、journal を利用しても結果が再現できなくなる。 上の例だと、 wirte と chmod が十分時間間隔を開けて到着したので write->chmod の順でファイルシステムに反映した結果を client に返したのだが、 この直後に system down を起こしたとしよう。 journal を実行する際には write と chmod は十分短い間隔で 要求されるので、 chmod->write の順で実行してしまったら、 同じ結果を得ることはできない。
File System は journal に保存された順序通りに 処理を行った場合と同じ結果を保証する機構が必要になる。 しかし、完全にシーケンシャル実行で実装してしまうと、 今度は IO Performance に問題が生じてしまう恐れがある。 これを回避するには、非同期書き込みモードでは十分高速な File System に対する journaling 機構である必要がある。
ファイル変更に関して、あらゆる事を journal に保存すれば、 ファイルシステムは完璧に復元する。 たとえばファイルへの書き込みに際して、 書き込みデータも、メタデータへの変更も、全て記録すれば ファイルシステムの復元は完璧になる。 このような journal の方式を Full Journaling と呼ぶ。
Full Journaling ではファイル保護は完璧になるが、 journal に保存するデータ量も半端ではなくなる。 全て journal に保存すると言うことは、 LFS に匹敵する data 量を journal として保存し、 さらにファイルシステムへの書き込みを行わなくてはいけない、 という事になる。 実質、性質の異なるファイルシステム2つに書き込んでいるのと 同じ状態になってしまい、 IO 性能に問題が出かねない。
このため、実用に供されている jfs の多くは、 Full Journaling を採用しない。
最初に犠牲になるのは user data だ。
Pre logging 型でも Post logging 型でも、 journal 内容の大半は user data になる。 このため、二重に書き込む量を減らそうと思ったら、 最初に対象になるのは user data になる。
Post logging 型の場合、 indirect block の更新も user data どうよう犠牲になることが多い。 Pre logging 型の場合、indirect block の更新情報は最初から存在しないので、 これは問題にならない。
このように user data を削除した場合を Metadata Journaling と呼ぶ。 Post logging 型の場合は、 Metadata Journaling と呼ぶと indirect block などの「管理情報」も 一部 journaling 対象から外される事が多い。
これらを journaling 対象から外した場合、 これらに対する更新は Softupdate と全く同じ規則を適応しなくては きちんと保護されない。 つまり、user data と indirect block を先に書き込み、 inode や allocation block に対する更新を後に行う。 inode と allocation block への更新は journal への書き込みでも構わないが、 この2つの順序を入れ替えることは許されなくなる。
ext3, ReiserFS, XFS の3つのファイルシステムは、 Post logging 型の Metadata Journaling を採用している。 また、IBM の Linux-JFS は Pre logging 型に近く、 やはり Metadata Journaling を採用している。
残念なことに、ext3, ReiserFS, Linux-JFS は、 書き込み順序が( Linux の VFS が間違っているそのままの状態なので) 間違っている。 このため、これら3つのファイルシステムは、 XFS に比べて破損確率が高い。 さらに残念なことに、これらの開発者は、 Journal とファイルシステムの実体に矛盾が生じて破損した場合、 Journal に破損が生じた と勘違いし、Journal のフォーマットを変更することによって 問題が解決すると信じている節がある。 実際には書き順が間違っているので indirect block 情報が破損して、 ファイルシステムに矛盾が発生したのに、だ。
彼らの信仰が誤っている事は簡単に判る。 SGI が作った XFS は Linux の VFS の問題点を解決するために、 VFS のほぼ全てを入れ替えた。 結果、XFS は圧倒的に低い破損確率を誇っている。 Journal で保存しているデータはほとんど変わらないにも関わらず、だ。 この事実は、問題が VFS(に定義されているデータの書き込み順序)にあって、 Journal のフォーマットにはない事を端的に表している。
残念ながら XFS も完璧ではない。 XFS はそもそもが Multi-Media データを対象とすることを目的に デザインされているため、 ファイルデータの Storage 上での連続性確保が優先されている。 このため、ファイルに対する overwrite を、 copy-on-modify 戦略ではなく同じ sector に対する上書きで実装している。 このため、この上書きの最中に電源断が生じると、 ファイルが壊れてしまう。
Linux オリジナルの VFS の書き順を「パフォーマンス」を理由に 正当化するものもいるが、 ext3, ReiserFS, Linux-JFS, XFS の 4つの実装の中で、 XFS が最高速度を出している、 という事実は彼らの主張が極めて誤っていることをも示している。
|
|
|
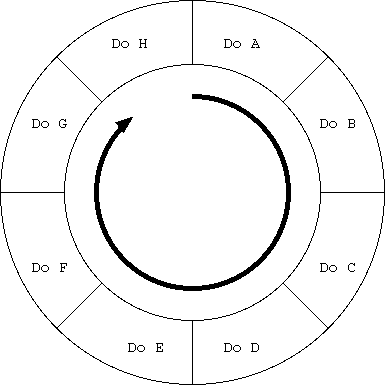
狭義の Journal の定義は図4.11 のようになる。
まず、ring buffer を用意する。 この ring buffer に行うべき処理を書き込む。 ring buffer が溢れたら、ring buffer の先頭から実行し、 その内容を解放していく。 実行順序を変えて、 『Do A』を実行する前に『Do B』を実行しても、 さらに追記するための領域は解放されない。
つまり FIFO の性質が付与されていて、 この条件を外すことができないのが Journal である。
もし、A のまえに B を実行しても影響がなく、 しかも B の実行の方が A よりも圧倒的に速かったとしても、 やはり A から始める必要があるのだ。
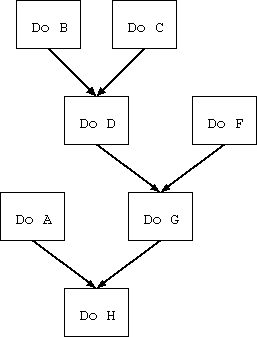
一方、intent log という発想がある。 これは図4.12 のようになっている。
intent log は FIFO ではなく、処理間の依存関係が保存されている。 たとえば、 図4.12 は 図4.11 と同じ順序で命令が到着した場合の intent log での管理構造を 表している。 この場合、 B, C, F, A は拘束を受けていないのでいつでも実行できる。 D は B, C が終了してからでは実行できない。 G は D, F が終了してからでは実行できず、 H は A と G が終了してからで無くては実行できない。 このような依存関係をリスト構造として保持する。
ここで、処理 I を追加しようとして領域がなかった場合、 A, B, C, F のどれを実行しても構わない。 実行された領域は(普通の malloc のメモリ管理のように)解放され、 再利用できるようになる。 たとえばここで B を実行したとしよう。 もしその結果処理 I を記述するのに必要な空き領域に足りなければ、 さらに別の処理(たとえば C)を実行すれば良い。
このように、intent log を使うと到着順序を保存しない、 Out Of Order な処理を行うことができる。 実行コストの高い処理を低負荷時に、 実行コストの低い処理を高負荷時に実行すれば、 トータルスループットは向上するので、 intent log の方が効率は良くなる。
ただし、intent log は依存関係を適切に処理しなくてはいけないし、 依存関係がちゃんとツリー構造になってくれる必要がある。 依存関係が適切に判断できない場合、 結局与えられた通りの順序でしか実行できないし、 仮に適切に判断できても、 結果が 単なる 1次元 link リストと変わらない構造になる事が多い、 と判っている場合は intent log を使う価値はない。
残念ながら、ファイルシステム更新はほとんどが 1次元 link リストに近い構造になることが知られている。 このため、特に Open Source のファイルシステムでは、 狭義の Journal を使っている。 ext3, JFS, ReiserFS, XFS の中に intent log を使っているものは、ない。
ファイルシステムの2つ目の尺度は Performance だ。
Performance 測定用ベンチマークは数多くある。 このため、この尺度に関しては難しいことは何もない、 と思っている人もいるようだが、 それは大きな間違いだ。 ベンチマークが沢山あるのは、 それだけ尺度が沢山あり、 どれが自分の目的に合致しているのかを正しく判断しないと、 ベンチマークの値が良いのに自分の利用目的では遅い、 などという現象が起きてしまう。
ファイルシステムの能力を記述する場合、 計測したい値は基本的に3種類ある。 1秒当たりの Metadata 処理能力 と 1秒当たりの directory entry 処理能力 、 1秒当たりの user data 転送能力 だ。 それぞれの性質自体は比較的簡単なので、 こちらを説明することにしよう。
まず、ファイルを指定するためには大抵のファイルシステムで、 PATH というものを処理しなくてはいけない。 PATH で指定された所にファイルが存在するのかどうかを調べなくてはいけないし、 ディレクトリの中に保存されているファイルとディレクトリの一覧を 提示するなどの処理もできなくてはいけない。 このため 1秒当たりの directory entry 処理能力 はファイルシステムの能力を記述するパラメータの1つになる。 基本的に計測単位は entry per second であることが多い。
一旦ファイルが指定できたら、
次にやらなくてはいけないことは
Metadata 処理
だ。
あるファイルを open させてもよいのかどうかの判断や、
そのファイルがいつ作成されたのか、
また書込みを許すのかどうかなど、
どのようなファイルでも共通で持っている管理用の「属性」
を操作・変更する能力を、
1秒当たりの Metadata 処理能力
で計測する。
一般にファイルの管理構造はファイルサイズには左右されない上に、
大抵の場合どのような処理でも似たような時間になるはずだ、
という前提があるらしく、
ここは「処理要求に対する応答の速さ」が計測対象になることが多い。
operation per second
で測ることが多い。
最後に、ファイルを open した後の、 内容データを読み書きする能力が問題になる。 これは1秒当たりの読み書きできるバイト数を計測する事が多い。 bytes per second で計測することが多い。
幸か不幸か、これら3つの値を別々に、かつ独立に、計測するすべはない。 そこで、 ベンチマークは、これらの計測に関してある一定の仮定をおいている。 その上で、自分達が測りたいと思っているものを計測している。 その方向性は大まかに言って、 上記の3種類の内どれか1つに強くフォーカスを当てるタイプ (IO Zone とか IO Meter とか言われるもの)と、 「平均的な」使われ方を調べた上で、 それに基づく負荷がどれぐらいすばやく処理できるのかを測るものの 2種類に分けられる。
これら2つの間に優劣はない。 重さを測るのに竹の物差しは使わないし、 長さを測るのに分銅を使わないのと同じことだ。
ファイルシステムの能力は、 ファイルシステムを構築している HDD などの物理メディアの性質、 転送速度、ファイルシステム処理が動いている計算機の CPU の性質や速度、メモリ量、 さらにファイルシステムをどの程度 robust に設計するかに 強い影響を受ける。
中でも判りにくい上にかなり深刻な影響を与えるのが、 実際に利用している物理メディアの性質と ファイルシステムが仮定している物理メディアの性質の差がもたらす 性能の低下だ。
そこで、これらの中のいくつかを取り上げて、 それらがそれぞれにどのように影響するのかを見てみよう。
Connectivity という単語が理解しにくければ、 『接続性』ではどうだろう? やっぱり判りにくい?うーん。そうかもしれない。
ファイルシステムを実装する物理メディアは、 実は計算機に対して永久の接続性を維持しているわけではない。 SCSI-1 規格の HDD のように計算機の電源が入っている限り、 SCSI デバイスとしてそこに存在し続け、 なおかつ容量や内容が変化しないものもあれば、 DOS マシンの floppy disk のように計算機に何ら通達なしに いきなりメディアが引き抜かれ、差し込まれるものもある。 それらの中間状態として、 MO や CD-ROM のように計算機側の都合で、 ある程度は reject を遅延できるものもある。
昔は、
「でたらめなタイミングで reject されるデバイスは
リムーバブルメディア」
とされていた。
これらに対してはあまり性能は要求されなかった。
ところが厭らしいものが現れた。
SAN
だ。
SAN とは、 従来「計算機の一部」として存在していた記録メディアを、 Fiber Channel(FC)などの高速シリアル線と Switch を用いる事で、 計算機の外部に引きずり出したものだと思えば良い。 特定の計算機の内部にいないので、 従来と違って複数の計算機を一度に同じ物理メディアに接続することができる。
SAN は従来の SCSI などよりも圧倒的に高速なメディアを使ってデータを 転送するので、 その処理速度ゆえの有利さがある。 さらに、 リムーバブルメディアのように Connection を切ることで、 HDD の集合体である Raid をあちらの計算機からこちらの計算機へと、 自在に切り替えることもできる。 数テラバイトのデータをボタンひとつであちらの計算機からこちらへ移動する 能力が付与されるのだ。
ここまでで我慢しておけばよかったのだが、 SAN はここにもう一つ機能を追加してしまった。 1つの Storage に、 同時に2つ以上の計算機がアクセスできるようにしてしまったのだ。
まぁ、確かに。 Storage に対する IO コマンドの発行主さえ判っていれば、 結果を誰に報告するべきなのかも判る。 SAN のレベルではこれ以上は何ら問題はない。 実装は、このレイヤーだけならばさしたる問題はない。
しかし、File System から見た場合、 これほど迷惑な代物はない。 File System に対する変更を行う場合に、 従来なら気にしなくて良かった排他制御やら、 キャッシュのコヒーレンシーやらを問題にしなくてはいけないのだ。
結局、 File System 上の何かに対して変更を加えたい場合、 まず writer lock というものを確保しなくてはいけなくなった。 writer lock を確保すると、 SAN 経由でそのメディアを共有している全ての計算機は、 writer lock の対象となった領域に関する Cache を破棄し、 アクセスがブロックされる。 ついで 変更が SAN 経由で物理メディアに書込まれ、 writer lock が解除される。
これは、File System から見ると、 物凄く短時間の内に Storage が remove されて、 また繋がる、 という状態が頻発するようなものだ。 しかも、厭らしいことに全デバイス単位ではなく、 一部分だけが都合に応じて remove されることになる。
「あぁ、なんだ。
問題になるのは変更したいポイントだけじゃないか。
ファイルを変更するにしても何にしても、
どうせ似たような排他制御は必要だったわけだし、
たいした問題じゃない。
どうせ同じファイルを変更する事は希だろう?」
と思ったあなたは、
SAN を舐めている。
つーか File System を舐めている。
あるファイルの内容を変更するには、 まずそのファイルを open しなくてはいけない。 ファイルを open するためにはまず、 指定された PATH を確認しなくてはいけない。 このため、root から その問題のファイルを指し示すポイントまでの 全ての参照対象になるディレクトリが reader lock の対象になる。
ついで、その最終的な directory entry から inode を取得し、 inode が保存してある Storage 領域に writer lock をかける必要がある。 Access Time の変更に備えるためだ。 ファイルの本体に対する writer lock を確保するのはこの後になる。
判るだろうか? i-node テーブルの一部に対して writer lock が必要なのだ。 可変長 Metadata を実装しているファイルシステムの場合、 ロック対象はそのファイルシステム全体に及ぶ。 どこが Metadata か判別のしようがないからだ。
一番厭らしいのは NTFS や FAT のように Metadata が directory entry の中にある場合だ。 ファイルを read only で open する場合でも directory の atime を変更する必要があり、 そのためには最低でもその directory に writer lock をかけなくてはいけない。
結局 SAN を使う場合は、 同時にアクセスするファイルが少ないように制御するのではなく、 同時にアクセスするディレクトリが少ないように制御しなくてはいけない のだ。 この制約は、 もし本当に実装可能な場合、 実はそもそも複数の計算機間で Storage を共有する必要性自体疑わしいぐらい、 実装が難しいものだ。
さて、SAN のように ずーっと繋がっていてくれる保証がない デバイスに対してファイルシステムを構築する場合、 パフォーマンスの観点から見ての悪影響は 1秒当たりの Metadata 処理能力 と 1秒当たりの directory entry 処理能力 、 が深刻なものになる。 1秒当たりの user data 転送能力 は、実は言うほど酷くならない。 他の計算機が変更したデータの Cache はどのみち reload しなくてはいけないので、 方針によらないからだ。
1秒当たりの Metadata 処理能力 も 1秒当たりの directory entry 処理能力 も、 Lock によって処理が先に進めないというシリアライズ問題と、 Cache が無効になる問題があり得るが、 深刻な状態を作り出すのは Cache の無効化の方だ。
たとえばここに 3台の計算機 A,B,C があるとしよう。 この3つが同時に同じディレクトリ上にある異なるファイルにアクセスしようと したとする。 3台はほぼ同時に PATH サーチを行うが、 仮に A が少しだけ他のマシンよりも速くサーチを終了させたとしよう。 当然、A は directory に対して writer lock をかける。
B と C も directory search は終了しているが writer lock をかけ損なった。 結果、A が open 処理をしている間 B, C は何もできない。 が、A の open 処理自体はすぐ終了する。 A の動作によって B,C の directory の cache は無効化される。
B,C は directory search を再度行わなくてはいけない。 directory の内容は A によって変更されたかも知れないからだ。 また、そのサーチは対象となる directory を探す事から始めなくてはいけない。 directory の大きさが拡大され、 その際に directory の Storage 上の位置が移動したかも知れないからだ。 B, C は作業を大幅に roll back せざるを得なくなる。
そして、B,C の内、早かった方(B としよう)が また directory に対する writer lock を 獲得し、C は同じ作業をまたしても再度行うことになる。
結果、A は 1度、B は 2度、C は 3度、 directory entry を読むことになる。
一般に n 台の計算機が同一directory に対して1度だけアクセスする場合、 directory を読む回数の最悪値は Σi=1ni になる。 これは n*(n-1)/2 になることから判るように、 計算機の台数の2乗に比例しており、 その頻度でアクセスパフォーマンスが悪化することが判る。
さらに、これが繰り返しになると事態はさらに深刻になる。
再び A,B,C の場合について考えてみよう。 今度は繰り返しアクセスがある場合だ。
A がファイルを読み込んだ後、 同じディレクトリに対してまたアクセスをしたいとする。 仮に A のこの要望が十分すばやく発行されたとすると、 A は B,C に比べて圧倒的に有利になる。 A には directory に関する Cache 情報が存在していて、 B, C と異なりこれを SAN 経由で読み込み直す必要がない。 ということは、 高い確率で再び A が directory に対する writer lock を獲得し、 B, C がまたしても読み込み直す事になる。
これらは A, B, C が協調して何か作業をしようとする場合、 深刻な現象を引き起こす。 A だけが処理を続け、 B, C は directory を読み込み続けるだけ、 という状態が発生する可能性がある。 一方で、A,B,C が協調して何か作業をしようとするのでなければ、 この 3台が同じディレクトリに対して繰り返しアクセスする必要はない。
基本的にファイルシステムは removable メディアに対して 効率よく動作するようにできていない。 これはファイルシステムの根元的な 仕様 だ。 そして SAN のようなメディアは「高速に remove/set を繰り返す」メディアだ。
もし、共有される事の多いファイルやディレクトリがあるならば、 nfs で共有することをお勧めする。 nfs であれば directory lookup などは Server だけが行うからだ。
Storage が HDD のような単体メディアの場合、 基本的な IO 単位は Sector である。 1 sector が何バイトなのかはメディアに依存するし、 メディアによっては物理フォーマットの段階ではじめて決定するので 必ずしも一意決定ではない。
しかし、まぁ、そうは言っても、 HDD の場合は 512byte だし、 230Mbyte MO も 512byte だ。 640Mbyte MO は 4096byte だし、 floppy disk は 256, 512, 1024, 2048, 4096byte のどれかである事が多い。
しかし、これが Raid、特に Raid4 や Raid5 になると IO の単位は遥かに大きくなる。 Raid4 や 5 は、複数の HDD に IO を分散させるために Striping 処理が行われる。 しかも CheckSum 構造が存在し、データの正常性がチェックされるので、 IO は CheckSum が管理している単位である Stride でしかできない。 このサイズは 1 HDD 当たり 1 Sector としても、 11 台の計算機であれば (CheckSum 分の 1Sector を除く)10台分、 5120byte が 1 IO の単位になる。
最小 IO サイズが大きくなると、 十分巨大なデータを IO する場合、 バイト単位の IO の速度は大きくできる。 HDD に限らず Memory であっても何であっても、 読み書きを行う『位置』の指定には相応のコストがかかる。 HDD はその『位置』へ移動するために Head Seek に数msec が必要だし、 Memory はアドレス指定に必要なコストだけなので 0.1usec 程度の 時間が必要になる。 このオーバーヘッドを IO の最小単位バイト数で割ると、 1バイト当たりのオーバーヘッドになるが、 オーバーヘッドは基本的に物理機構に依存するだけなので、 IO の最小単位が大きいほどオーバーヘッドは相対的に小さくなる。
逆に最小 IO サイズが大きくなると、 小さなデータを IO するためにも最小 IO サイズ分はアクセスする必要がある。
この性質は 1秒当たりの Metadata 処理能力 に深刻な悪影響を受ける。 1秒当たりの directory entry 処理能力 、 と 1秒当たりの user data 転送能力 は、その定義性質上、 有利になる場合と不利になる場合がある。
最小 IO 単位が大きいと、大きな user data、 並びにdirectory entry 数の多い directory に対する IO 性能は 向上する。 一方、小さな user data に対する IO 性能はむしろ低下するし、 それは directory entry 数の少ない directory に対する IO 性能も 同様である。 ただし、一般にはこれらのパラメータは「サイズの大きな」場合が 計測対象になることが多い。 ので、ベンチマーク上は最小 IO サイズが大きくなる事は これらの数値には有利になるだろう。
問題は Metadata 処理能力だ。 基本的に Metadata は小さい。 そもそも 512byte でさえ巨大すぎるのだ。 余計なデータの IO は、 そのまま参照・更新のコスト、 並びにキャッシュメモリの利用効率の悪さとして現れる。 利用効率の悪さはそのまま IO 頻度の向上に繋がるので、 さらに効率が悪くなる。
デバイスと通信する際に用いられる通信メディアの性能は 1秒当たりの Metadata 処理能力 、 1秒当たりの directory entry 処理能力 、 1秒当たりの user data 転送能力 の3つに同じような性質を与える。 基本的に通信メディアの性能が高ければ高いほど、 物理メディア本来の性能に近い通信速度でデータを IO できるようになる。 ただし、ここら辺の表記はかなり煩雑でややこしい。
たとえば、SCSI。SCSI-1, SCSI-2 辺りまではまぁいいとして、 Wide-SCSI, Ultra-SCSI, Ultra-Wide-SCSI と来て、 Ultra-160, Ultra-320(企画段階), Ultra-640(予定) と来られると、もう何がどうしてどれが早いのやらさっぱり判らない。
さらに IDE と E-IDE, ATA-33, ATA-66, Ultra ATA/100, Ultra ATA/133 と どちらがどう早いのか、と聞かれたらもうさっぱりだ。
ましてや、ここに iSCSI と FiberChannel が出てくると…。
表記がややこしいのは動作クロック、同時に転送するビット幅など 表現に自由度がありすぎるためだ。
最近の流行りは基本的に一度に転送するビット幅は、 1bit のシリアル化が進んでいる。 そこで全ての規格を bit per second(bps) で表現してみよう。
| 規格 | 通信速度(bps) |
|---|---|
| SCSI I | |
| SCSI II | |
| SCSI III | |
| Wide SCSI | |
| Ultra SCSI | |
| Ultra Wide SCSI | |
| Ultra160 | 160Mbytes/sec = 1280Mbps |
| Ultra320 | 320Mbytes/sec = 2560Mbps |
| Ultra640 | 640Mbytes/sec = 5120Mbps |
| IDE | |
| E-IDE | |
| ATA-33 | |
| ATA-66 | |
| Ultra ATA/100 | 100Mbytes/sec = 800Mbps |
| Ultra ATA/133 | 133Mbytes/sec = 1064Mbps |
| iSCSI | TCP/IP 上に SCSI コマンドを実装するため、 TCP/IP の転送速度に依存 |
| FiberChannel |
Fiber Channel 自身の速度によって決定する 1Gbps 2Gbps 10Gbps が知られている。 |
物理メディアの IO 能力が 通信メディアの通信能力よりも低ければ、 もう少し正確に言うと 通信メディアには 「60%以上使うのは難しい」 という一般則があるので通信メディアの通信能力の 60% よりも低ければ、 物理メディアの IO 能力を 100% 使うことができる。
最近の物理メディアはコントローラが接続されており、 そこにはメモリが存在している。 当然、このメモリはキャッシュとしても使われている。
物理メディアから一度読み出されたデータは キャッシュに読み込まれる。 外部からこのデータに対するアクセス要求があった場合、 このデータがキャッシュにある限り、 物理メディアにアクセスすること無くキャッシュから読み出される。 キャッシュメモリからの読み出しは物理メディアからの読み出しよりも高速なので (というか、高速でない場合はキャッシュの意味はないので、 キャッシュがある場合はメモリの方が早いに決まっているのだが)、 この場合は物理メディアに対する読み出し性能は向上する。
また、書込み要求されたデータは、 一旦キャッシュに保存されてから物理メディアに書込まれる。 もし、物理メディア自身に相応容量のコンデンサーなどが積んである場合、 キャッシュ上のデータをいきなり物理メディアに書込まず、 データが上書きされたり、隣接する領域に対する書込み命令が来るまで 遅延させることで、 物理メディアに対する書込み性能を向上させることができる。
キャッシュは
1秒当たりの Metadata 処理能力
、
1秒当たりの directory entry 処理能力
、
1秒当たりの user data 転送能力
の3つに対して基本的に性能向上をもたらすはずだが、
実は必ずしもそうとは限らない。
前に書いてあることと主張がおかしいように聞こえるが間違ってはいない。
ようするに問題はキャッシュがヒットするかどうか、にある。 キャッシュは 同じ領域に対する読み込み・書込みが繰り返し発生した場合 にしか効果がない。 たとえば、巨大なファイルがあってそのサイズはキャッシュよりも大きく、 それに対する読み込みが一度だけ発生する場合、 読み込みキャッシュは全く働かない。
この場合、 データ読み込みが完全に終了した後には、 メタデータなどファイル以外の部分に対するキャッシュが 完全に無くなってしまうので、 ファイルデータに対するキャッシュが働かないだけでなく、 Metadata や directory entry の処理能力にも悪影響を及ぼす。
なかなか面白いのは、 File System がデータを読み込んだ場合、 あるいは File System がデータを書込もうとした場合、 そのデータは File System 自身もキャッシュを保持している事が多い。 結果として物理メディアのキャッシュは読み込みに際しては あまり効果がないことが多い。 File System 上のキャッシュに先にヒットしてしまい、 物理メディア上のキャッシュにヒットする確率が落ちてしまうのだ。
File System の Functionality とは何か。
File System のお仕事は、 Storage とユーザーの間に入って、 「ファイル」と言われる管理構造を構築することにある。 ファイルをどのように実装するかはすでに説明した通り、 なん通りもある。
しかし、これだけでは困る。
実際には Storage は物理的な存在でしかないので、 壊れることもあれば時代遅れになることもある。 壊れる前にバックアップは取りたいし、 時代遅れになったら最新のもっと容量の大きい、速度の早いものに リプレースしたいだろう。 しかし、これらの作業のために File System のサービスが停止するのも できれば避けたいはずだ。
disk を新しく手に入れたら必要に応じて File System のサイズを大きくしたいだろう。 サービスを停止させずに。 調子の悪そうなディスクがあったら取り外したいだろう、 サービスを停止せずに。
このように、 File System が提供するべき「ファイルシステムとして以外の」 機能のことを Functionality と呼ぶことにする。
File System に要求される Functionality にはいくつかの種類がある。 ここでは以下の3通りについて説明する。
これらの機能を組み合わせることでバックアップ、ミラーリング、 などの実現が可能になる。
しかし、これらの実装は決して簡単ではない。 実運用中のファイルシステムは、 メモリ上にキャッシュを持っており、 それらが適切にディスクに反映されるタイミングを適切に制御しないと、 論理的不整合が発生するからだ。
たとえば、SnapShot 機能を考えよう。
Ram 上の Metadata 情報に Dirty なものが残っているときに、
Storage のイメージを SnapShot したとしても、
そのイメージはファイルシステムとしての用をなさない。
Ram 上ではすでにあるファイルが消されており、
その領域は他のファイルによって再利用されてしまった場合、
この瞬間の Storage 上の SnapShot は、
「古いファイルが存在していることになっていて、
しかもその中身は新しいファイルによって上書きされている」
という状態を作り出してしまう。
では、OS が管理している Cache 上に dirty data がなくなれば良いのか? 実は必ずしもそうでもない。 動作中の Application が、ファイルにデータを書き出そうとしているが、 これが完了するにはあと 30回 write(2) を繰り返さなくてはいけない という場合、 この動作が完全に終了するまでは SnapShot の獲得は意味をなさない。 ファイルシステムとしては矛盾がないだろうが、 Application としては矛盾しているからだ。
この場合、重要になるのは どこで割りきるか になる。 割りきるポイントは、 ファイルシステムの直下 と ファイルシステムの直上 の2種類が考えられる。 これ以外の部分はファイルシステム単体では実装できないからだ。
結果、乱暴に言って都合6通りの Function があり得ることになる。 以下、それらについて述べていく。
ある指定された瞬間のファイルシステムのイメージを固定し、 その状態に対して、それ以降 read-only でアクセスできるようにしつつ、 一方ではちゃんとファイル更新することもできて そちらはそちらで参照できる、 という状態を作り上げる機能を Snap Shot 機能と呼ぶ。
Snap Shot の基本的な戦略は、 基本的にファイルシステムに対する更新量は、 ファイルシステム全体に占める割合としては小さい というものだ。 この条件下では、 1つの Storage 上にほとんどの部分を共有している、 同一ファイルシステムに関する2つの version を同時に保持できる。 これが可能になると、 Snap Shot を確保した直後は2つの version は 完全に同じイメージなので 2つの version の管理を始めるために必要な初期化さえ行えれば、 極短期間にある特定の瞬間の Storage の image を固定することができる。
Storage Snap Shot は、ファイルシステム以下、 物理的 HDD よりも上のどこかの層でこの Snap Shot 機能を実現する方法で、 基本的には Logical Volume、あるいは Logical Block と呼ばれる アドレスを Physical Volume あるいは Physical Block と呼ばれる アドレスに対して仮想化することで実装される。 Snap Shot を取ると、それ以降は Copy On Modify の戦略にしたがって、 変更要求のあった部分をどうにかしてコピーするわけだ。
この実装はさらに logical address table を多重化して、 新しく書込み要求のあった領域に対する physical address を 新しく割り当てる という、新しい block を別の場所に確保する方式と、 新しく書込み要求のあった領域のコピーを待避領域にコピーし 古い SnapShot 側の logical table を書き換えていく という、古い block を別の場所にコピーする方式に大別できる。 Linux の LVM などは 古い block をコピーする方式である。
Snap Shot を確保できた Storage (正確には Logical Volume と呼ばれる Storage を仮想化した部分) は、 イメージがこれ以降変化しないので、 バックアップなど、 長時間かかる IO を要求しても(IO性能に問題は出るかも知れないが) 論理的な問題は発生しない。
Storage Snap Shot の問題点は、 File System の状態とは無関係に SnapShot が取れてしまう点にある。 File System を async モードでマウントしている場合、 あるいは Linux VFS のように どうにかして dirty data の完全 sync をサポートしていない、 そういうバグのある状態では、 メモリ上に存在する dirty data を全て Storage に書込まない限り Storage 上のイメージは整合性を持っているとは言えない。 sync を実行してもその直後に write が発生した場合のように sync から snap shot 処理までの間がatomic に処理されない場合、 あるいは そもそも sync が適切に処理されない場合、 Storage Snap Shot は全くと言って良いほど価値を持たない。
Storage Snap Shot が LVM レベルでの SnapShot を実現しているのに対して、 File System Snap Shot は File System に対する request の入り口レベルでの Snap Shot を保証している。 つまり、File System に対する request に Snap Shot 要求が発生したら、 File System 自身が Snap Shot をマーキングして、 Snap Shot 要求以降に行われた変更と Snap Shot 要求以前に行われた変更を分離し、 Snap Shot 要求以前に行われた変更だけからなる 仮想的な read only file system を構築してくれる という機能を提供する。
File System Snap Shot をサポートするには、 Snap Shot の際に Metadata のコピーを取り、 Snap Shot 以降の変更は新しい Metadata 領域に対して反映すると同時に 古い Metadata が利用している storage block に関しては新しい 側では利用不可能にする(上書き要求に対しては Copy-on-Modify を行う) という方法を取ることになる。
従来の FFS のように Metadata 領域が巨大で storage 上に分散していると、 Metadata 領域のコピーをとるのでもかなりの時間がかかる。 このコピーの間他のサービスを受け付けることはできなくなり、 実用的ではない。
File System Snap Shot をサポートする File System は root inode 方式を用いているのが一般的である。 root inode 方式であれば、 一番始めにコピーする必要があるのは root inode だけで、 それ以外のものは全て Copy on Modify で実装することができる。 root inode 方式において本当の意味で metadata なのは root inode 情報だけだからだ。
File System Snap Shot の場合、 sync 機能が制限を受けていると、 Snap Shot の確保自体は ram 上の dirty data として 確保されるだけかもしれない。 結果、File System としての整合性は崩れなくなるが、 Storage Image と File System SnapShot との間の整合性が ない危険性が出てしまう。
File System Snap Shot 機能を用いる場合、 Snap Shot を要求した際には dirty page を全て Storage に書込む事も要求でき、 なおかつその機能が壊れていないことが要求される。 でないと意味がない。
今、HDDを2台使っているとしよう。 各120Gbyteなので合計240Gbyteだ。 しかし、そろそろ容量が足りなくなってきた。
そこで、HDDを買い足すことを考える。 200Gbyteほど買い足せるとしよう。 問題はこのHDDをどのように現在使っているファイルシステムのツリー上に追加するか、 という点だ。
旧来のunixでは、異なるメディアも既存のディレクトリツリー上に マウントすることができた。 マウントしたディレクトリの下には新しいデバイスが存在し、 そのディレクトリ下に作り上げたディレクトリツリーとその中にあるファイルは、 全て新しいデバイス上に作成できた。
が、これでは新しいディスク200Gbyteと古いディスクの空き容量の80Gbyte
の合計280Gbyteというサイズの単体ファイルは保存できない。
280Gbyteのファイルを格納できるのは唯一 280Gbyte以上の容量を持つHDDだけになる。
これは不便だ。