|
|
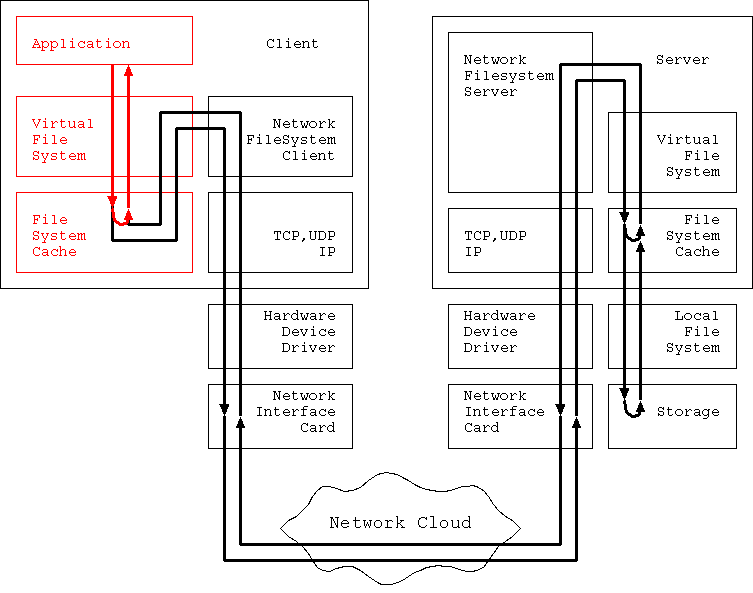
本章では 図2 の赤い部分、 Application からリクエストが発行されてから Client File Cache までの経路に焦点を当てる。
この部分が本領を発揮するのは主に読み込み時だ。 read only mount/export で読み込み専用であることが判っている ファイルシステムに対するアクセスは、 この経路だけで話が済むかどうかが大きく関与する。
書き込みリクエストが発行された場合、 書き込みたいデータは Server 側に転送され、 Storage に格納されないと書き込みが確実なものとならない。 このため、Client File Cache が純粋な書き込みパフォーマンスを 向上させるために役立つことは、ほとんどない。 Application、厳密には file io を処理してくれるライブラリが、 書き込みリクエストをマージして大きな書き込み単位に直す、 などの処理をすでに行ってくれるように、 既になっているからだ。
厳密には Client Delegation という方法があって、 その場合にはある程度効果があり得るが、 この場合は Client 側で「ちゃんと書けなかった場合」の 責任を取っている。 また、見掛け上の Turn Around Time を減少させる Delegation 方式は、 最後の最後、client が shutdown する際に、 write dirty な cache をすべて server に反映する必要があるので、 shutdown にかかる時間が伸びる、 という弱点もある。
この部分の性能を支配しているパラメータは大まかに言うと3つある。 nfs protocol、OS、そしてハードウェアである。
厳密に言うと、Application がリクエストを馬鹿な手順で発行しない、 というのも性能を向上させる上では重要なのだが、 とりあえずそこは nfs の 外 という事で、 今回は考慮の対象外とすることにしよう。
nfs protocol の選定は重要だ。
たとえば Sun NFSv2 は Client Cache の実装を全くサポートしない。 素で NFSv2 を使うと Client Cache のヒット率は 0% になってしまう。 もちろん、lock daemon 等とセットで使うことでそこそこの Client Cache を実装できるようになるのだが、 すべての Client OS がこれをサポートしてくれる保証はないし、 仮にサポートしていても、 管理者の中で最もスカポンタンな人間が案の定、 あるいは管理者の中で最も有能な人間が疲労からうっかりと、 設定を間違え、 一番やっかいな瞬間にそのことが露呈するだけの話だ。
従って、nfs protocol は注意深く選定しなくてはいけない。 たとえば NFSv3 や v4 は最初から Client Cache を念頭においた 構造になっているし、 SMB(CIFS) なども同様だ。 これらを利用しない積極的理由はあり得ない。
逆に DAFS などのプロトコルの場合、 通信層が InfiniBand などを使い、 圧倒的に高速であることが前提になっている。 実際、InfiniBand は PCI などの「バス」の代価品としての 側面も持っている。 実質的にメモリアクセスの本の数分の一の速度で Server と通信できることになっているので、 その場合は Client Cache 自体が不要になる。 Client Cache にメモリを割くよりも、 別の目的にメモリを利用した方が全体のパフォーマンスにとって 都合が良い可能性が高いのだ (もちろん、十分量のメモリがあるなら Client Cache に利用するのも損ではないだろうが、 いまだかつてそのような都合の良いシステムが存在したためしがない)。
Client OS によってはコストとの兼ね合いなどが理由で、 特定の nfs protocol しか利用できない場合もあるかも知れないが、 少なくともその protocol が実用に足る物かどうか、 ぐらいは評価してからの採用でも遅くはないはずだ。
Application によっては OS は決まってしまう、 という向きもあるかも知れないが、 厳密にはそんなことはない。 OS の選定はやはり重要である。
まず、OS は 安定している 事が重要だ。安定していて 各種 Power Saving 機能 がついているとなお良い。
Client File Cache はあくまでも「キャッシュ」である。 これはつまり OS がダウンしたら全部消えてしまう、 と言うことだ。 当然、Client の電源を毎日落としていたら、 翌日起動したときには File Cache の中身は空であり、 Cache Hit 率は 0 に落ちてしまう。 つまり nfs protocol がどんなに優秀で、 OS がどれほど優れた Cache Memory 管理を行い、 Cache Memory 用にどれほど多くのメモリを与えようとも 毎日落とさないと実用に足らない OS では、 意味がないのだ。
OS が安定していても消費電力がフルパワー状態では、 環境問題がやかましい昨今では連続運転は許されまい。 Server ならばともかく Client なのだから。 というわけで Client には Power Saving 機能も重要になる。 しかし例えば Stand by 機能とか、 サスペンド機能とかはこの場合は役に立たない。
サスペンド機能のように CPU も NIC も停止してしまう場合、 Client は Server との通信もすべて停止してしまう。 しかし Cache がちゃんと機能するためには Server 上の情報と Cache の情報が整合性を保っている必要があるので、 何らかの通信を行ってこの整合性を確認する必要がある。 サスペンド状態ではこの確認通信が全くできなくなるので、 Cache の整合性に関する保証がない。 結果、レジュームした後の OS は Cache のイメージを全く信頼できず、 すべて破棄することになる。
結局、計算するべき内容がない場合は CPU をパワーダウンさせる (halt を行う)、 HDD の回転を止める、 モニターのパワーを抑える、 などのきめ細かい制御をしてくれる、 しかし通信などのレベルではすぐ回復してくれる、 OS が必要になる。
キャッシュは基本的にメモリ上に確保される。 もちろん、中には AFS や DFS のように Client キャッシュが HDD 上にも 確保されるものもあるが、 これらはどちらかというと例外だ。 と言うことは、OS のメモリ利用効率が問題になる。
Windows 3.1 の系譜である 95, 98, Me や、MacOS 9.5 までなどは、 実メモリサイズサイズが決まると、 そのうちのどれだけがファイルキャッシュに使われるのか決定する。 一旦ファイルキャッシュに使われると決まったらそこはアプリケーション に使われることはない、がアプリケーションがメモリを必要としなくても そこがファイルキャッシュに使われることもない。
unix ではかなり昔から、 ファイルキャッシュとアプリケーションの実データ領域の利用は 動的に割り当てられていた。 ファイルキャッシュとアプリケーションの 実データ領域利用バランスは状況に応じて変化する。 このため、ファイルキャッシュ上にあるアプリケーションの プログラムイメージが存在した場合、 そのページは「そのまま」実行のために参照され、 無駄な IO が抑えられている。 この方式を採用している OS としては、 MacOSX や Windows NT/2000/XP なども挙げられる。
当然だが unix タイプのメモリ管理方式の方がメモリ利用効率は高い。
2000年に入ってからは、 より積極的な共有戦略を使うことがトレンドになっている。 NetBSD の UVM/UBC や Linux の 2.4.10 以降の vm などは その好例である。
OS は扱える最大メモリ量に上限値がある。 例えば、Windows 98は 512Mbyte 以上のメモリを与えても適切に 利用する能力がない。NT も 1Gbyte だか 2Gbyte だかの辺りに 同様の壁がある。 2000 になると 4Gbyte のメモリをフルに利用できる。 これらの制限は、 OS を作られた当時のハードウェア性能から考えると やむをえない点もあるが、 新しい環境に適合しないという事実は変わらない。
IA-32 アーキテクチャーと言われる CPU 用の OS は これらの壁の他にも 32bit の壁というものが存在する。 IA-32 自身は 48bit のアドレスを扱えるのだが、 ビット幅が中途半端だしプログラムが複雑になるので 大抵の OS は 32bit 以上のアドレス空間を利用しない。 この空間の大きさは、 そのまま OS が利用できるメモリの大きさを規定し、 それがそのまま File Cache のサイズを規定する。 この制約を外そうと、一部キャッシュに利用している物理メモリを わざと仮想空間上にマップしない戦略を取る vm もあるが、 その努力は CPU の仮想アドレス幅が 64bit になれば水泡に帰することが 判りきっているので(同じことは 16bit アドレス空間、20bit アドレス空間 の時にもあった。当時はバンク切り替え、という方式だったが)、 果たして正しい方向性なのか、は疑問が残る。
新しい OS は、より広大なメモリを、 より効率よく使い回せるようにプログラムされている。 より新しい nfs protocol の利用も可能になる。 メモリの利用効率はそのまま OS の動作効率に繋がるので、 何らかの互換性上の理由や技術的発展が起こらなかったのでない限り、 効率を求めるならば新しい OS を利用するべきである。
ハードウェアのタイムスケールは人によって感覚が異なるが、 計算機を5年以上利用している人ならば 新しいハードウェアは物理的制約が少ない という事実に異論はないだろう。 それは単に計算機の演算速度だけではなく、 実装できる物理メモリの大きさにも影響を与える。
一般に物理メモリが小さいと、 複雑な管理戦略に基づいた、 何も保持していなくてもそこそこの容量を要求する、 しかしより効果的な戦略を利用することはできない。
例えば、ファイル名を考えてみよう。 ファイルキャッシュに 1Mbyte も利用できないような世界では、 一度に覚えておけるファイル名もたかだか数百個でしかない。 この場合は線形探索を行った方が余計なメモリを消費しない。 しかしこれが 1Gbyte ならば、 Hash 関数を用いた検索方法を使わなくては遅くて使い物にならない。 さらに広大な空間の場合、 平衡木のようなものを使って先に分類する必要があるだろう。
このようにハードウェアの性能は OS が使うべきアルゴリズムを決定する。 もし、十分なハードウェアリソースが与えられなければ、 OS はその実力を発揮できないだろう。
物凄く乱暴に以上を総括するとこうなる。
「Application base で Client OS を選定するのであれば、
最高の HW と最新の OS を使え」
何と言うか…身も蓋もない(^^;)でも理由はある。
実は、次の章でも Client に関しては同じ結論が出てくる。
結局、Application を固定してしまうと、 それが動く OS と nfs が決まってしまい、 選択肢がある一連の「シリーズ」の中から選ぶしかなくなるのだ。 ところが、この手の「シリーズ」というのは、 新しいものほど新しい HW を要求し、 その替わり過去の OS の弱点が直してある。 Windows ならば 98 より 2000、Mac も 9.5 より X なのだ。
結局、時間軸上に並べると新しいものほど良い性能が出るようになり、 代償として HW の要求が厳しくなるようにできているのだ。 軸がたくさんあるように見えて、 実は選択肢はたった一本の右肩上がりの直線上にすべて載っていたわけだ。 これでは手の打ち様はない。
これは何と言うか…皮肉な話である。
大抵の場合、Client は安いマシンを用意したがる。 わざわざ Server を立ち上げるのは、 省コストのためである場合が多いからだ。 難しい作業は Server に任せ、 Client は少しのメモリとローパワーの計算力で済ませようという魂胆。
でも Application を Client 側で動かしてしまったら、 その段階で「難しい作業」を Client 側で実行しているのだ。 nfs 用の Cache が大量に必要なのは、 その結果に過ぎない。
もし、Application を固定しないのであれば、
OS も自由に選択できるようになる。
この場合は、
unix 系の OS かあるいは MacOSX、Windows ならば 2000 か XP を選択し、
メモリを物理限界まで乗せてしまうに限る。
「そんなには使わないんじゃ…」
などというケチケチしたことを言ってはいけない。
あなたには使うつもりがなくても、
間違いなく OS は使ってくれる。
その上で、OS のスクリーンセーバーは ブランク(真っ黒にするだけで何も表示しない) かあるいは、もし可能ならば モニターへの信号を切ってしまう ものを選び、 HDD の回転は不要になったら即刻停止するように設定して、 低消費電力で静寂なマシンにしておくのだ。 そうすれば誰もそのマシンのスイッチが入りっ放しだとは思わないから、 Cache が勝手に消される心配もない。
さてしかし、 Client File Cache のヒット率は、 どんなに頑張っても 100% にはならない。 一番最初の一度 だけはどうしても Server と通信し、 ファイルのデータを取ってこなくてはいけない。
また、書き込みの場合は Server 側にデータを転送しなくては、 書き込みは絶対完了しない。 と言うわけで次の章ではいよいよ通信部が相手になる。